-
A (very) brief history of LMMs

Large Multimodal Model (LMM): A large-scale model consisting of multiple modalities, typically a mixture of image processing and generation models, combined with a Large Language Model (LLM). See Chip Huyen’s post for a great dive into the concepts: Multimodality and Large Multimodal Models (LMMs). Update 10th July 2025 This is a quick addition to my…
-
AWS UK Card Payment Woes

My Monzo bank card expired recently. Somehow many of my services that were tied to it – including Google Pay – seemed to have magically updated themselves to the new card number. Bravo 🥳 Unfortunately however the same cannot be said for AWS. I use AWS for hosting my family data backups of photos etc.…
-
The question that just will not die 💀😮💨

Please excuse the lengthy rant but I got nerd sniped at work today and need to finish getting something off my chest. “When will we be able to replace programmers?” You see, every so often this idea comes back around, usually because of some new visual code generator tech. Obviously it’s current run is down…
-
Audible ‘Connect to a Device’ misbehaving?

This has been driving me nuts for a while now and I finally figured out what’s going on and how to fix it. TL;DR If you find that the option in the Audible app to ‘Connect to a Device’ does not appear as you might expect then it seems this can be caused by another…
-
0x80070422 might not be what you think

I’m writing this having just spent some unwanted effort resolving issues with the Xbox App, Microsoft Store and Windows Update on my Windows 11 PC. Like many people when I encountered an error using the Xbox App I turned to Google to see how to solve it. I was even given an error by the…
-
What is a ‘Senior Developer’?

TL;DR Hire the behaviours, train the technical skills It’s all arbitrary and entirely dependent on what you need from a ‘Senior Developer’. That said, my experience has shown me that – to me – being a Senior Developer is mainly about behaviours. Sure, technical ability is a significant part of that, but for the day-to-day, being able to cover…
-
Explaining TypeScript
I recently fielded an interesting request that I thought might have some value outside of a private conversation. Can you explain to me what TypeScript is? As you would to a small child please 😂 Samuel Hughes – https://www.linkedin.com/in/samuel-hughes-16029b163/ This reminds me of a maxim I have encountered in a number of organisations to assist in…
-
Making the jump
Over just the past few weeks I have been asked on three separate occasions now for advice on making the move from being a hands-on software developer to a primarily management-focused role. This has given me significant cause to consider this subject and I feel it warrants its own post to fully capture my thoughts.…
-
Simple Linear Regression in Power Query
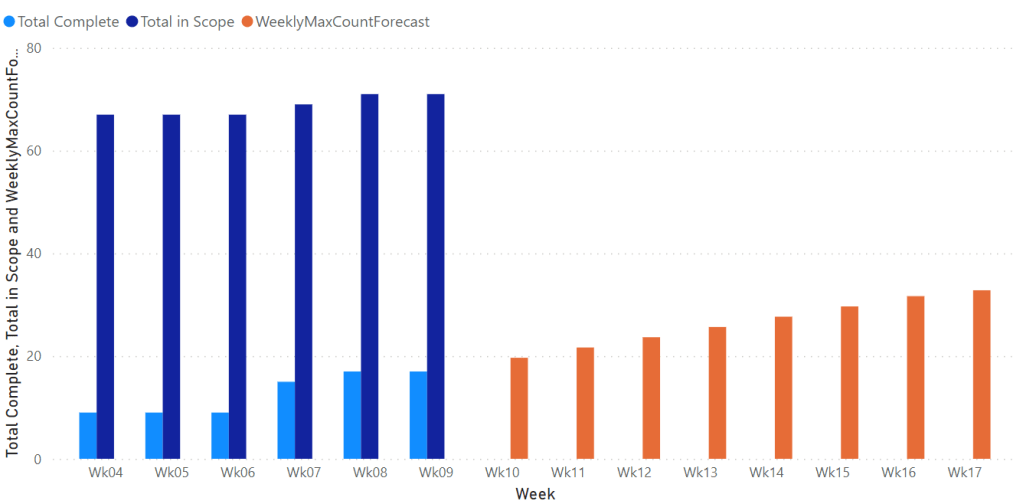
Some Background I’ve been doing some work setting up a custom work item tracking process in Azure DevOps to support our current way of delivering change. Azure Boards doesn’t really support the sort of customisations we require and so I’ve broken most of the usual Agile tools such as the burndown charts. As a result…
-
Run! The Distributed Systems are coming!

You can avoid the fate of those that fell before you This is a letter to my fellow engineers, specifically those who operate in the front-end world. This letter is sent with love, but carries a message of deep foreboding. It is a warning and yet it is a message of hope, that there is…

Helping with the taxing tech problems that get less attention
