
Category: Patterns and Practices
-
Explaining TypeScript
I recently fielded an interesting request that I thought might have some value outside of a private conversation. Can you explain to me what TypeScript is? As you would to a small child please 😂 Samuel Hughes – https://www.linkedin.com/in/samuel-hughes-16029b163/ This reminds me of a maxim I have encountered in a number of organisations to assist in…
-
Simple Linear Regression in Power Query
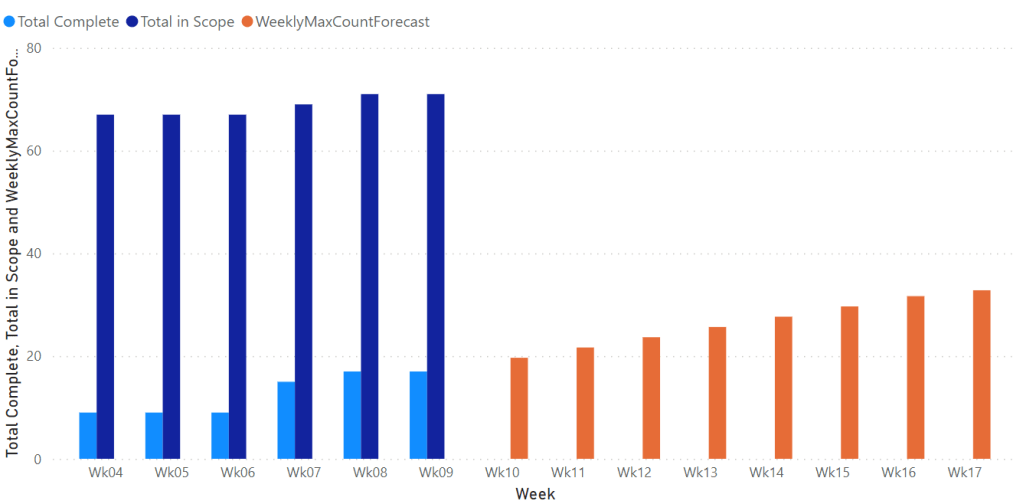
Some Background I’ve been doing some work setting up a custom work item tracking process in Azure DevOps to support our current way of delivering change. Azure Boards doesn’t really support the sort of customisations we require and so I’ve broken most of the usual Agile tools such as the burndown charts. As a result…
-
Run! The Distributed Systems are coming!

You can avoid the fate of those that fell before you This is a letter to my fellow engineers, specifically those who operate in the front-end world. This letter is sent with love, but carries a message of deep foreboding. It is a warning and yet it is a message of hope, that there is…
-
Concepts of Compliant Data Encryption
Introduction This is a somewhat lengthy article that is intended to help anyone who is taking their first steps into learning about encrypting sensitive data in a compliant environment such as meeting PCI DSS requirements. The hope is that this is an effective stepping stone into the dry, dry world of encryption standards and compliance.…
-
Babeling in defence of JavaScript
And so it goes, the eternal question “What is wrong with JavaScript?” and the inevitable, inescapably droll, reply: Nothing![] == '' // -> true[] == 0 // -> true[''] == '' // -> true[0] == 0 // -> true[0] == '' // -> false[''] == 0 // -> true — Scott Hanselman 🌮 (@shanselman) June…
-
A functional solution to interfacitis?
/ˈɪntəfeɪsʌɪtəs/ noun noun: interfacitis inflammation of a software, most commonly from overuse of interfaces and other abstractions but also from… well… actually it’s mostly just interfaces. An illness of tedium Over the years my experience has come to show me that unnecessary abstractions cause some of the most significant overheads and inertia in software projects.…
-
Demystifying AI – The AI explosion
This is an article I had originally written as part of a stream of work that has now been put on hold indefinitely. I thought it a shame for it to languish in OneNote. What’s with all this attention to Artificial Intelligence then? Well that is a very good question. To be perfectly frank, not…
-
FileFormatException: Format error in package
OK so we’re all completely clear on what this error means and what must be done to resolve it right? I mean with a meaningful error like that how can anyone be mistaken? Oh? What’s that? You still don’t know? Let’s be a bit more specific: System.IO.FileFormatException: Format error in package Better? Didn’t think so.…
-
Things I wish I knew 10 years ago: Abstractions
We need to talk about abstractions The main reason I decided to start this blog is that I have begun working for a company that has genuinely challenged many of my assumptions about how software should be developed. I have spent much of my career learning from the more prominent voices in software development about…
