
Category: Uncategorized
-
Audible ‘Connect to a Device’ misbehaving?

This has been driving me nuts for a while now and I finally figured out what’s going on and how to fix it. TL;DR If you find that the option in the Audible app to ‘Connect to a Device’ does not appear as you might expect then it seems this can be caused by another…
-
0x80070422 might not be what you think

I’m writing this having just spent some unwanted effort resolving issues with the Xbox App, Microsoft Store and Windows Update on my Windows 11 PC. Like many people when I encountered an error using the Xbox App I turned to Google to see how to solve it. I was even given an error by the…
-
Simple Linear Regression in Power Query
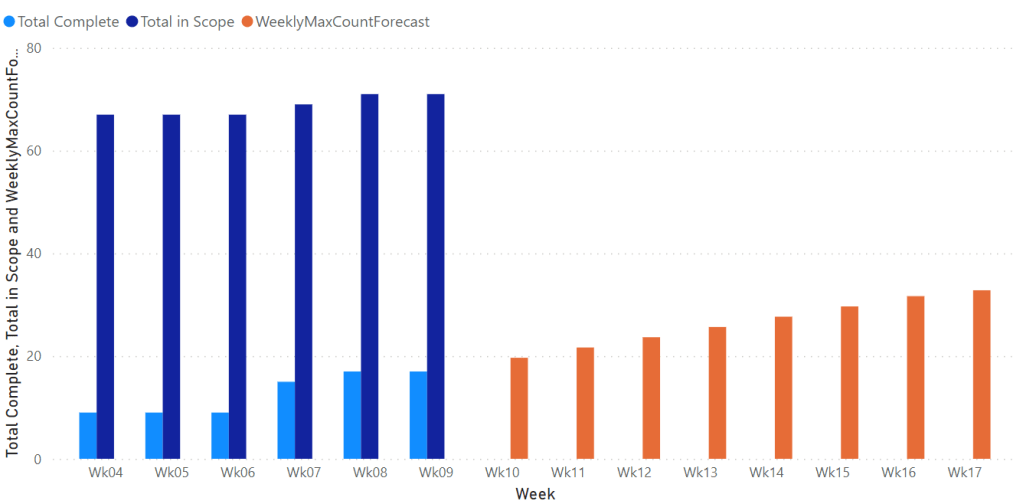
Some Background I’ve been doing some work setting up a custom work item tracking process in Azure DevOps to support our current way of delivering change. Azure Boards doesn’t really support the sort of customisations we require and so I’ve broken most of the usual Agile tools such as the burndown charts. As a result…
-
Run! The Distributed Systems are coming!

You can avoid the fate of those that fell before you This is a letter to my fellow engineers, specifically those who operate in the front-end world. This letter is sent with love, but carries a message of deep foreboding. It is a warning and yet it is a message of hope, that there is…
-
Improvement Sprints
or Shuhari Sprints Nothing worth doing is easy and anything worth doing is worth doing well … or so the sayings go. My personal experience certainly proves to me that these are more than simple soundbites and I am fairly confident in those sayings having more than a ring of truth to most IT professionals. So…
-
LinkedIn Error “There was a problem sharing your update. Please try again”.
Obscure Error I was trying to reply to a comment on an article I posted to LinkedIn the other day and kept hitting the error “There was a problem sharing your update. Please try again”. Just a note to help anyone who might come across this error when attempting to post an update to LinkedIn,…
